Estatística descritiva para product managers - Parte 3
Seus dados não são o que parecem ser

Se você acompanhou a Parte 1 e a Parte 2, já entendeu que a média é "traiçoeira" e que o desvio padrão é quem nos conta a verdade sobre a consistência do nosso produto.
No texto anterior, usamos o exemplo do tempo de checkout do nosso app de delivery: [5, 7, 6, 8, 10, 5, 9, 8, 7, 12 minutos]. Vimos que a média era 7,7 minutos, mas com uma variação importante.
Agora, vamos elevar o nível. Para descrever dados com precisão, precisamos parar de olhar para o todo como uma massa única e começar a "fatiar" esses dados.
Nessa parte 3, falaremos então de posições: percentis, quartis e o boxplot — conceitos que vão refinar a sua capacidade de leitura de dados e te ajudar a enxergar padrões que a média esconde.
Percentis: onde a "mágica" (e o problema) se esconde
A média tenta resumir tudo em um número. O percentil te diz exatamente onde cada usuário está na fila.
O percentil é uma medida que divide a sua amostra ordenada (do menor para o maior) em 100 partes. Se dizemos que o P90 (percentil 90) do nosso checkout é 10 minutos, significa que 90% dos usuários terminam a compra em 10 minutos ou menos. Consequentemente, os outros 10% levam mais que isso.
Visualmente, é assim que isso se parece em uma distribuição de dados real (note como os dados se esticam para a direita, criando uma "cauda"):
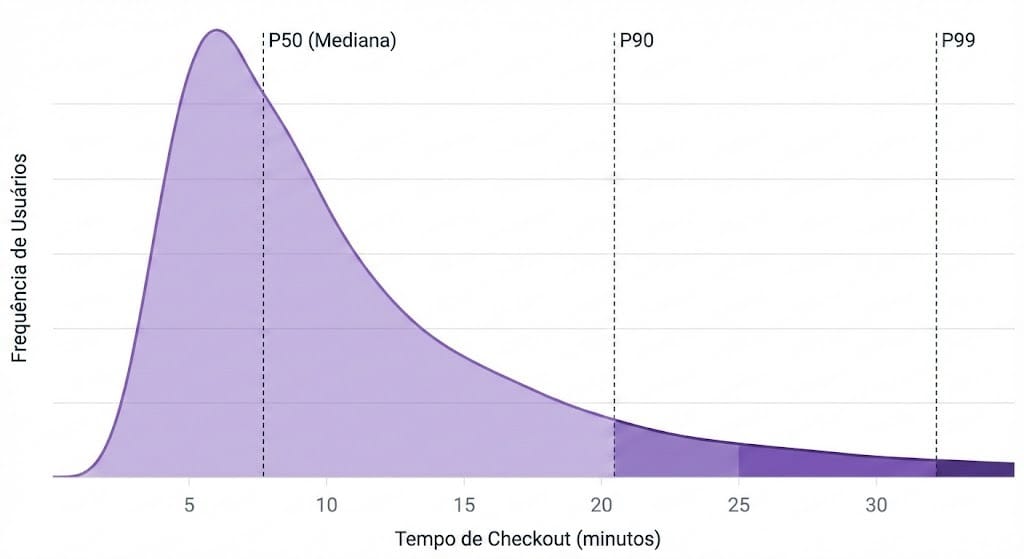
Por que o mercado fala tanto de P95 e P99?
Olhando para o gráfico acima, você pode pensar: "Se a grande montanha de usuários está segura à esquerda, por que me preocupar com o final da cauda (P99)?".
A resposta é dinheiro e retenção. Em produtos digitais, o P99 (o 1% com pior experiência) raramente é um usuário aleatório. Muitas vezes, esse 1% representa seus usuários muito engajados — clientes que têm carrinhos de compra gigantes, históricos de dados longos ou configurações complexas.